เทคโนโลยี•Android Authority•2 พ.ย. 2568
Google Mixboard เปิดให้ใช้ในไทยแล้ว! กระดาน AI ระดมสมองที่ใหญ่และสนุกกว่าเดิม
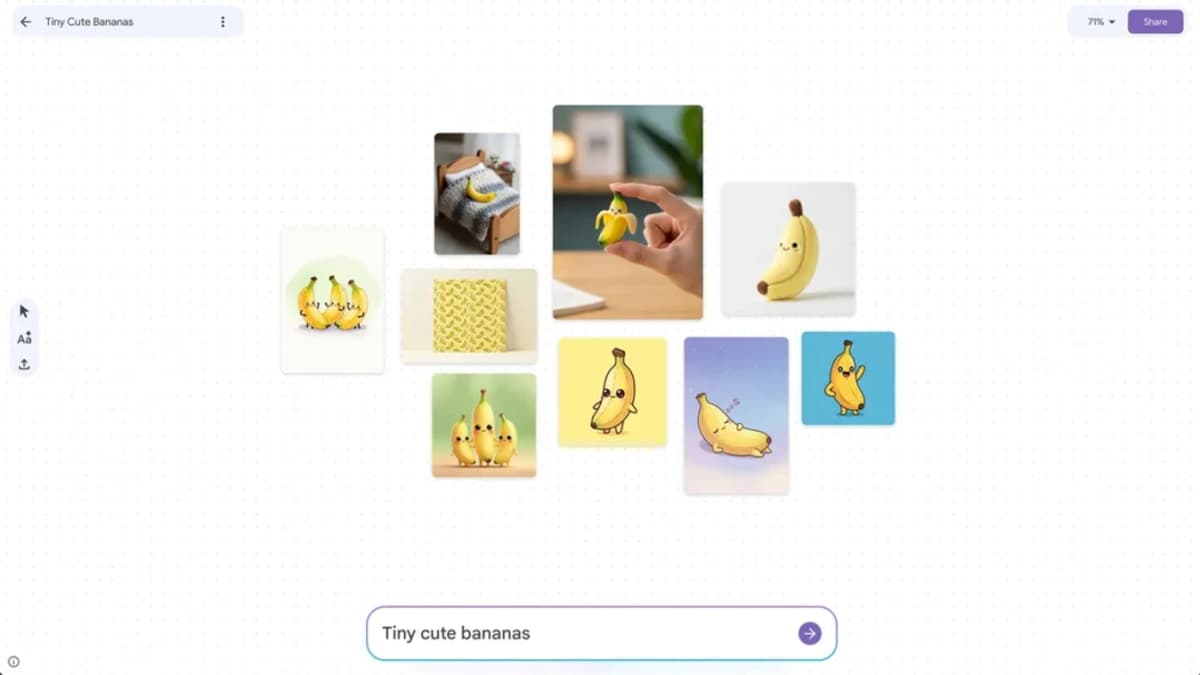
Google เปิดตัว Mixboard เครื่องมือ AI สายสร้างสรรค์ที่เคยทดลองในวงแคบ ให้คนทั่วโลกกว่า 180 ประเทศได้ลองเล่นแล้ว โดย Mixboard คือกระดานอัจฉริยะที่เราสามารถโยนรูปภาพ ข้อความ แล้วสั่งให้ AI ช่วยระดมสมอง ต่อยอดไอเดีย หรือสร้างภาพใหม่ ๆ ขึ้นมาได้เลย การอัปเดตครั้งนี้ไม่ได้มาเล่น ๆ เพราะนอกจากจะขยายพื้นที่ให้บริการแล้ว บอร์ดยังมีขนาดใหญ่ขึ้นถึง 4 เท่า ทำให้มีพื้นที่เหลือเฟือสำหรับสเก็ตช์ภาพ แปะรูป reference หรือจดโน้ต ก่อนจะให้ AI ช่วยผสมผสานไอเดียทั้งหมด จากที่เคยเป็นแค่โปรเจกต์ทดลองเงียบ ๆ...
0•3 นาที•โดย Suphansa Makpayab














-cropped-1761740810135.jpg?w=1200&q=75)



